This section assumes that you've read Submitting a Shapefile Update, which shows how a contributor, say a data manager for a county, can quickly prepare an update archive for sending to you, the database maintainer. A shapefile in the archive will contain only the records that the contributor modified. The archive will also contain the new files linked to those records, which is convenient since the the folder hierarchy is preserved in the ZIP file.
On the receiving end you'll use the Compare with other layers function in almost the same way. The reference shapefile is actually an up-to-date master copy of the database, perhaps one that hasn't yet been published. It could very well contain updates the current contributor hasn't seen. Also, the reference will be compared against just one shapefile, the one extracted from the contributor's update archive. The compare dialog might appear as follows:
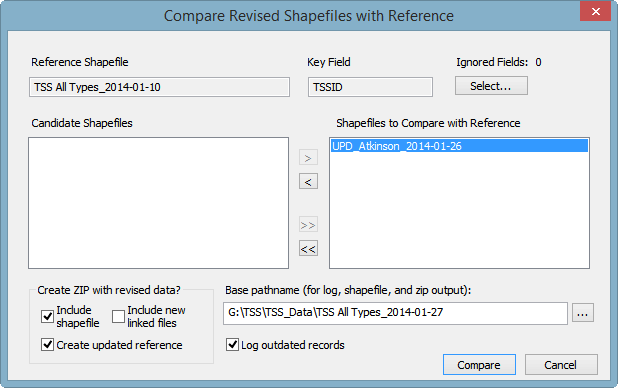
Another difference is the checked box labeled Create updated reference. As the label suggests, both revised and unrevised records will be copied to the output shapefile, with unique keys assigned to the new records. Only the maintainer processing an update will want to select this option, which creates a new database snapshot -- in this case, one named TSS All Types_2014-01-27. The new snapshot might be named differently if you'll shortly be using it as the reference for processing another update. The output shapefile must have a different name than that of the current reference.
It is especially important that you leave option Log outdated records checked. That's because the contributor could have edited records originating from an older snapshot. To prevent records with older (or identical) UPDATED timestamps from being ignored, you may need to edit them yourself to incorporate information added by another contributor. This will refresh their timestamps, insuring they will be used for the new snapshot.
Although creating the snapshot and ZIP prematurely would be harmless, you can first perform the operation with boxes Include shapefile and Create updated reference unchecked. That will create just a log detailing what records and specific field values would change if the records in TSS All Types_2014-01-10.shp were replaced with the corresponding ones in UPD_Atkinson_2014-01-26.shp. Note that this log will likely differ from the one the contributor produced, which is contained in the update archive, UPD_Atkinson_2014-01-26.zip. As you'll see below, it's important that you base your review on the log you've generated.
Clicking "Compare" in the above dialog will perform the file scan and generate a log namedTSS All Types_2014-01-27.txt. The next prompt summarizes the results:
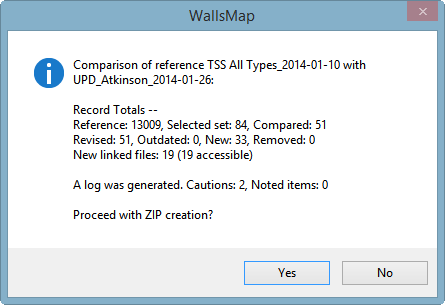
Initially you'll select "No." Then, at the next prompt, you'll select "Yes" to have the program open the log in your text editor. While reviewing the log, you may want to make changes to a few records in the update shapefile, and for that reason I suggest temporarily changing the editor's name in the Name for Signing Timestamps dialog to the contributor's name. I recommend against routinely disabling timestamping.
Non-trivial changes might involve merging information supplied by different contributors. For example, beneath the list of changed field values in a record, you might see this caution message:
UPDATED_ |2013-12-30 21:04:21 George Veni --> |2013-12-28 07:15:17 G. Atkinson| *** CAUTION: Although revised, the record's UPDATED time is earlier than that of the reference. It won't be used. |
As it stands, this record will be ignored when the updated reference is written. But this could be a mistake. In fact, in all cases where the reference shapefile's last updater (name at left) is not the current contributor (name at right), you'll need to take a closer look. Even if Veni's edits had been older than Atkinson's edits (producing no caution), Atkinson couldn't have seen them if they were newer than the reference he used to create his update shapefile. By examining the log inside the update zip you can determine the date of that snapshot, which will appear on a line near the top of the file:
Reference Shapefile: TSS All Types_2013-12-01 (Date: 2013-12-01, Key Field: TSSID) |
This tells you that Atkinson's snapshot was too old for him to see any edits made by others after that date. For guidance on how to merge the information others may have provided, you can examine Atkinson's log entry for that record to see what fields he actually edited and what their prior values were. If he made only a minor correction, you can replace the update record with the reference's version, then repeat or copy that correction. As a general rule you should only revise the update shapefile and never the dated reference, which should be set non-editable.
To help determine whether or not a proposed memo field update needs to be reconciled with other updates, you can perform a side-by-side comparison using a utility designed for this purpose. This can be as easy as a few mouse clicks in quick succession. The compare feature is described under Editing Memo Field Content. If the log shows that a long report stored in a memo was updated by the contributor, and you would like to see exactly what was changed, you can compare it against the same snapshot the contributor used. But in any case you want to compare it with the version in the current snapshot, and that's usually sufficient. You can do this very quickly as described in Comparing Memo Field Text.
Beneath the compare log's list of changed records will be the list of new records, if any, showing the values of non-empty fields. Recall that records with empty key values are recognized as new records by the compare function. Unique keys will be assigned after the log is written and you've chosen to continue with shapefile and ZIP creation. A directive named FLDKEY in the reference's template component specifies how a key is constructed.
In the information listed for a new record you might see this:
*** CAUTION: The COUNTY and NAME field values match that of a record in the reference: UVA0232. |
In the TSS database it's not often that two different karst features in the same county have identical names, so you'll need to examine this record closely to avoid a possible duplication. The use of generic feature names, like "cave lead" can cause this message. More seriously, another contributor could have already added the feature, with the addition being newer than the contributor's snapshot. Or perhaps the existing record was missed because the feature was in a different category, or was unlocated and not visible in the map view. Another possibility is that the current contributor changed a feature's category from, say, Shelter to Cave, and instead of moving the original record to the Cave shapefile (copy to layer, then delete), decided to create a new record for it. This would cause a duplication if the old record was deleted from the shapefile instead of flagged for removal (NAME prefixed with asterisk). Unfortunately, these kinds of mistakes are hard to catch when the proposed name doesn't exactly match that of the existing record.
To repair such duplications, you'll need to replace the blank key with the one already assigned. Then you can run the compare function again to see if a merge of information is needed. (To override the read-only status of the key field, you can either edit the update shapefile's template or use the advanced option described in Name for Signing Timestamps.)
A similar situation that might require a manual key assignment is indicated by this message:
*** CAUTION: The following records have non-blank keys not found in the reference:
UVA0239 Uvalde: unnamed sinkhole . . . etc. |
This means that another contributor removed the record (and thus the key) from the database, perhaps realizing that the "unnamed sinkhole" was already represented by a different record. Such records will not be exported at all, nor will their field contents be listed in the log. You'll need to check the update shapefile to see if any new information for this feature was added, and if so, determine where it belongs.
In the section of the log listing changes to existing records, you'll occasionally see a note similar to this one:
COUNTY |Terrell| --> |Crockett|
*** NOTE: Changing the COUNTY value will require that the database maintainer create a new key. |
Since the COUNTY value is used for key generation, you're alerted whenever it changes. If the new county is recognized as one existing in the Texas_Counties shapefile (or the name Unknown reserved for unlocated features), the compare function on the maintainer's end will automatically replace the key with a new one. Otherwise the process of creating a new snapshot will abort with an error message. The contributor might see the note in the log, but no action is required if the change is legitimate.
Once you're satisfied with the condition of the update shapefile, you can run the compare again and confirm that you want to proceed with ZIP creation.
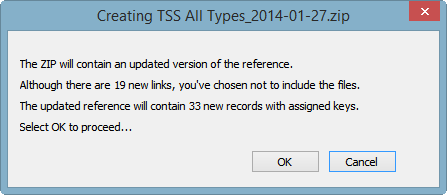
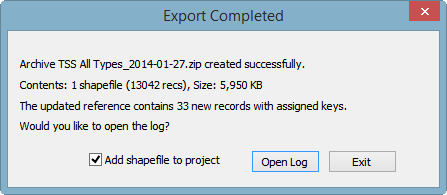
The compare log will have listed, within each record summary, the pathnames of files whose links were either added or removed. The new pathnames also appear at the end of the log in two groups: "Accessible Files" and "Inaccessible Files (links broken)." If there are files in the latter group, you'll know that you haven't finished copying files from the update archive to their standard locations (possibly reconditioning them in the process -- see below). In any case, your final step might be to open a table view of the output shapefile, right-click on each of the appropriate memo field names and select "Find broken image links."
Initialization of Ignored Fields
The Compare dialog in the above example will show that no ignored fields have been selected. Those would be fields whose values are either copied straight from the reference or initialized. Since their values in the compared files are ignored, you'll see nothing about them in the compare log. If you use this feature routinely, you can insert one or more FLDIGNORE directives in the reference's template component, with each specifying a field to ignore by default. The directive also has an optional initialization parameter that's relevant only when you've selected the Create updated reference option. For example, in the directive
.FLDIGNORE PROTECTION "|TNC_Protection::TNCMEMO|"
TNC_Protection is assumed to be a polygon shapefile layer with a field named TNCMEMO. If an output record's point is found inside the polygon of a record in TNC_Protection, then the PROTECTION field of the output record will be initialized with the content of TNCMEMO. The source and destination fields in this case can be memo fields. The initialization only happens in new records and in records whose locations are being revised. The PROTECTION field, like the key field, is not intended to be directly edited. A major benefit of this feature is that the TNC_Protection shapefile, which can be very large, doesn't need to be part of the released database project.
Exporting Category Shapefiles from the Snapshot
The final step in preparing a database project for release might be to split the new snapshot into a set of editable shapefile layers based on the values of certain fields -- convenient for labeling, toggling visibility, and targeting searches. This is most easily done by opening the snapshot by itself and then exporting it using a set of prepared export templates. The TSS uses specially-named templates, such as Export_TSS Caves.tmpshp, Export_TSS Sinks and Cavities.tmpshp, etc., to select only specific records in the snapshot to include in the output. The templates accomplish this with directives containing expressions of the form "=(value1|value2|...)" following a source field name. The only significance of the special names is that whenever a template with prefix "Export_" is selected by browsing a folder's content, the Output file box of the Export dialog is automatically filled with the correct pathname, say ...\TSS Caves.shp. This saves time and helps avoid errors.
TSS Conventions Regarding Image File Size and Format
Upon receiving an update, you might consider the approach TSS has taken with image files. The "Save for Web" function in Adobe Photoshop has proved to be an effective tool. For map images, the preferred format is PNG-8 (8 colors if grayscale or up to 256 colors if not). This isn't the standard "true color" PNG, or PNG-24, which is generally good for archiving. If the original is a 2-color bitmap, it must be converted to grayscale before it's resized. After resizing it should have the resolution needed for a viewer to see all important details and text, possibly after opening the file as a document and zooming to specific regions. The widths of map images, therefore, can range from 600 to 5000 pixels or larger. For photos, JPEG (JPG) remains the best format option. The longest dimension of a linked photo is typically 600 to 800 pixels, with a few reaching 1024 pixels.